
Published on sigoverrun.com — April 2026
1. Introduction: The Operator Leverage Thesis
A skilled penetration tester spends roughly 85% of their engagement time on tasks that are procedurally deterministic: running port scans, fingerprinting services, testing default credentials, crawling web applications, correlating CVEs against discovered software versions. The remaining 15% — lateral thinking, chaining vulnerabilities, exploiting business logic — is where human expertise is irreplaceable.[1]
The penetration testing market sits at roughly $2.5–3 billion in 2025, projected to reach $6.25 billion by 2032.[2] Yet 32% of companies still test only annually. The cybersecurity talent shortage is acute — and it's getting worse. Meanwhile, 48% of cybersecurity professionals now identify agentic AI as the single most dangerous attack vector.[3]
The premise behind our platform is simple: automate the 85% so a single operator can focus on the 15% that matters. Not replacing penetration testers — amplifying them. One skilled operator, augmented by an autonomous multi-agent system, should match the throughput of a 10-person red team while maintaining the same (or better) finding quality.
This isn't a wrapper around nmap with a chatbot. It's a ground-up platform where LLM-powered agents reason about targets, formulate hypotheses, execute experiments, and validate findings through a rigorous evidence pipeline. This post walks through the architecture, design decisions, and engineering challenges of building such a system.
Scope disclaimer: This post covers architecture and engineering patterns. We deliberately omit implementation details of our reasoning chains, attack pattern ontology, and validation thresholds — those represent years of security research encoded as software. What we share here are the structural decisions that any team attempting this class of system will face.Interface LayerReact 18 + TypeScript + TailwindCSS + Nivo + FastAPI WebSocketDashboard22 pages, 54+ componentsREST APIFastAPI, JWT, RBACCLICampaign mgmt, ShellCampaign OrchestratorLLM mission planner • DAG scheduler • Dynamic concurrency • Phase budgetSENTINELSafety, ROE, Kill <5sDAG SchedulerCycle & stall detectionToken BudgetPer-phase, adaptiveAgent Clusters — 15 clusters, 76 sub-agentsCustom ReAct loop • LLM reasoning • Skills-on-demand • Cross-agent discoverySCOUTRecon (6)ORACLEThreat Intel (4)BREACHNetwork (5)SPIDERWeb/API (8)PRISMVuln Research (5)FORGEExploit Dev (6)HAVOCFuzzing (4)NIMBUSCloud (5)SKELETON KEYAD/Identity (6)PHANTOMC2/Post-ex (8)GHOSTEvasion (4)NOMADMobile (5)LENSCode Review (4)SCRIBEReporting (5)ANVILTooling (4)Validation EngineMulti-stage pipeline • Evidence grading • Adversarial reviewSTAGE 1StructuralSchema checkSTAGE 2DedupCross-agentSTAGE 3EvidenceGraduated gradingSTAGE 4ReviewAdversarial LLMIntelligence LayerReasoning chains • Causal graph • Vuln prompts • Escalation pathsReasoning EngineChains, reflector, compressionKnowledge BaseSkills, RAG chunksOutput AnalysisParsers, diff analyzerTool Execution SandboxDocker + gVisor • Network isolation • 30+ verified toolsnmapsqlmapnucleinetexecimpacket+25 moreLLM Integration — LiteLLMPer-role temperatures • Air-gap capable • Adaptive budgetClaude APIReasoning, planningLlama / MistralLocal, speed tasksNeo4j 5.xKnowledge GraphPostgreSQL 16Findings & ConfigRedis 7.xCacheNATS JetStreamEvent BusMinIOArtifacts
Figure 1 — Platform architecture. Six layers from interface to storage, connected by an async event bus. Agents never touch the network directly — all tool execution flows through the sandbox.
2. Layered Architecture: Why Six Layers
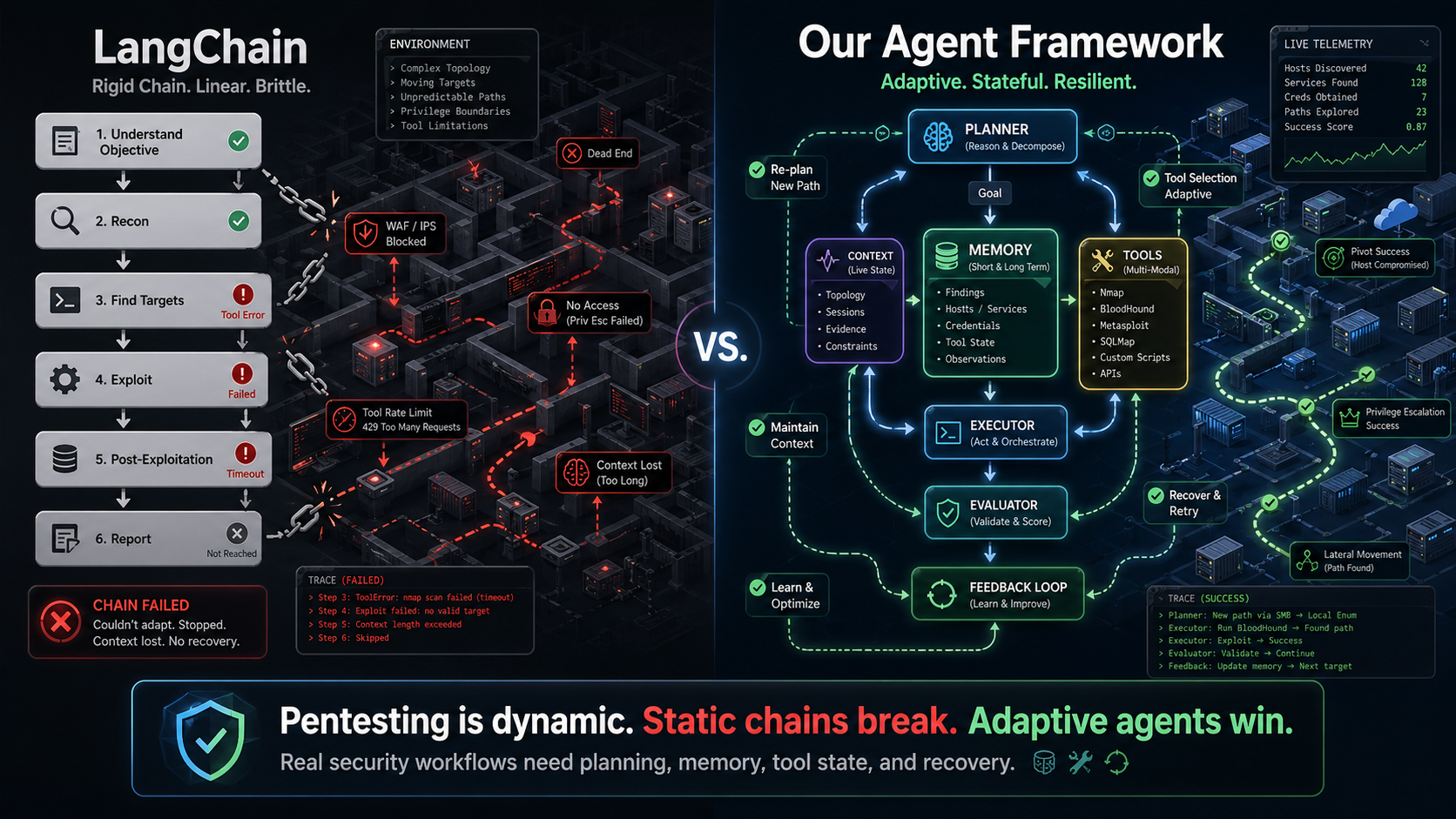
Early prototypes used a monolithic design: one agent, one loop, one LLM call per action. It worked for toy targets (DVWA, Juice Shop) but collapsed on real infrastructure. Google DeepMind's research on multi-agent failures is relevant here: unstructured multi-agent networks can amplify errors up to 17.2x compared to single-agent baselines.[4] The failure mode was instructive: the agent would context-window itself into confusion after ~15 steps, mixing reconnaissance data with exploitation attempts and losing track of what it had already tried.
The solution was strict separation of concerns across six layers, each with a single responsibility:
| Layer | Responsibility | Key Property |
|---|---|---|
| L6 — Interface | User-facing surfaces (dashboard, API, CLI) | Stateless presentation |
| L5 — Orchestrator | Campaign planning, task scheduling, safety | DAG-based execution |
| L4 — Agents | Domain-specific reasoning and tool execution | Autonomous ReAct loops |
| L3 — Validation | Finding verification and evidence grading | Zero false-positive guarantee |
| L2 — Sandbox | Isolated container execution for tools | Security boundary |
| L1 — Knowledge | Persistent storage, graph DB, event bus | Shared state |
The critical insight: agents (L4) never touch the network directly. Every tool invocation passes through the sandbox layer (L2), which runs in an isolated Docker container with gVisor kernel filtering. Every finding passes through validation (L3) before reaching the operator. The orchestrator (L5) controls which agents run, in what order, with what resource budget.
2.1 Why Not Microservices?
Each layer is a logical boundary, not a deployment boundary. The entire system runs in a single Python asyncio process (plus external databases). This was deliberate:
- Latency: Agent reasoning requires sub-millisecond context switches between tools, knowledge queries, and LLM calls. Network hops between microservices would dominate the execution profile.
- Shared memory: Agents need to share discoveries in real-time. An agent discovering an endpoint must make it immediately visible to all other agents, not after a pub/sub round-trip.
- Debuggability: When an agent makes a bad decision at step 47 of a 200-step campaign, you need a single stack trace, not distributed tracing across 15 services.
The event bus (NATS JetStream) provides async notification for cross-cutting concerns — broadcasting discoveries, emitting telemetry, triggering webhooks — but the hot path is always in-process.
3. The Platform in Action
Before diving into the technical details, here's what the system actually looks like in operation. These screenshots are from the current dashboard build, captured during runs against lab environments.
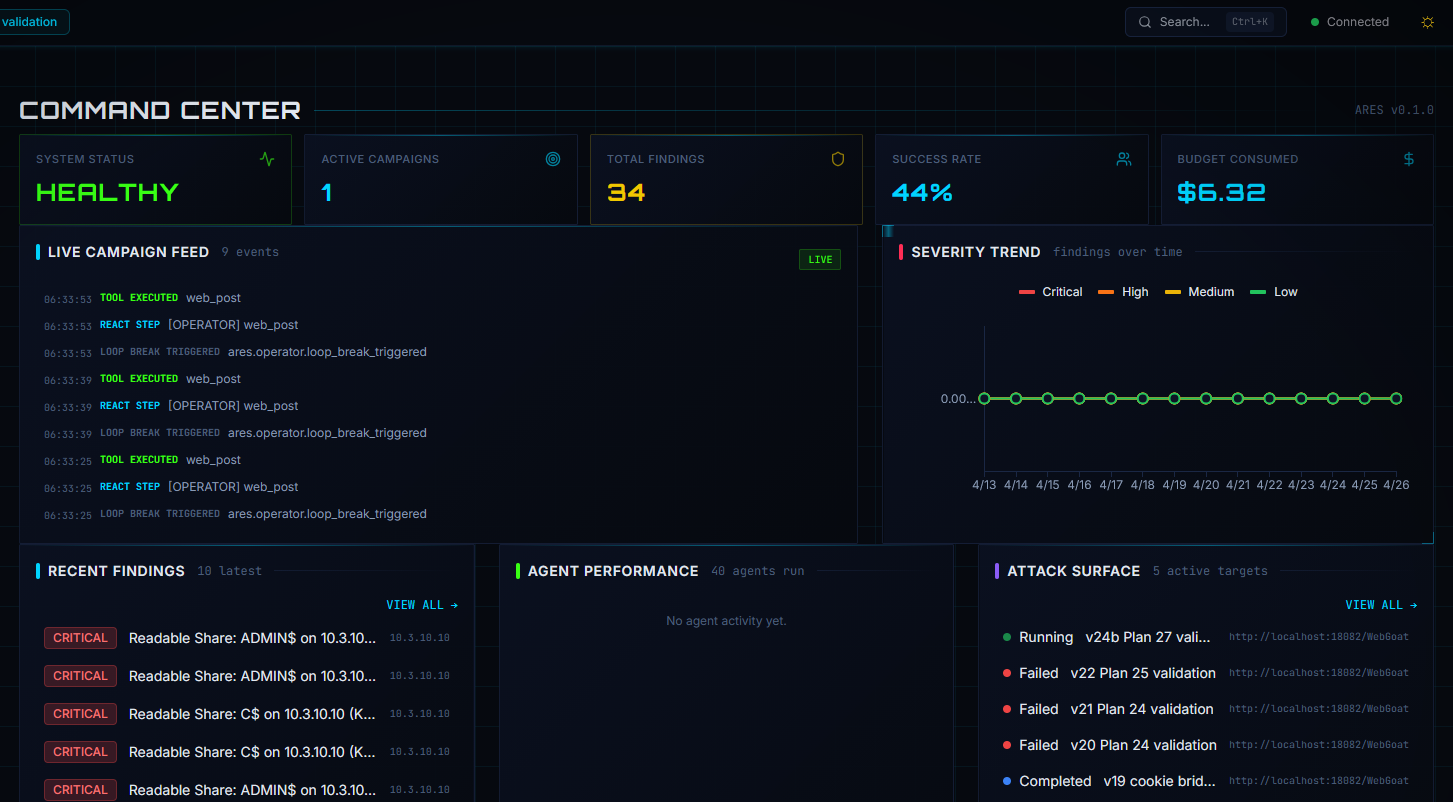
ADMIN$, C$) on a domain controller during an internal AD engagement against the GOAD lab.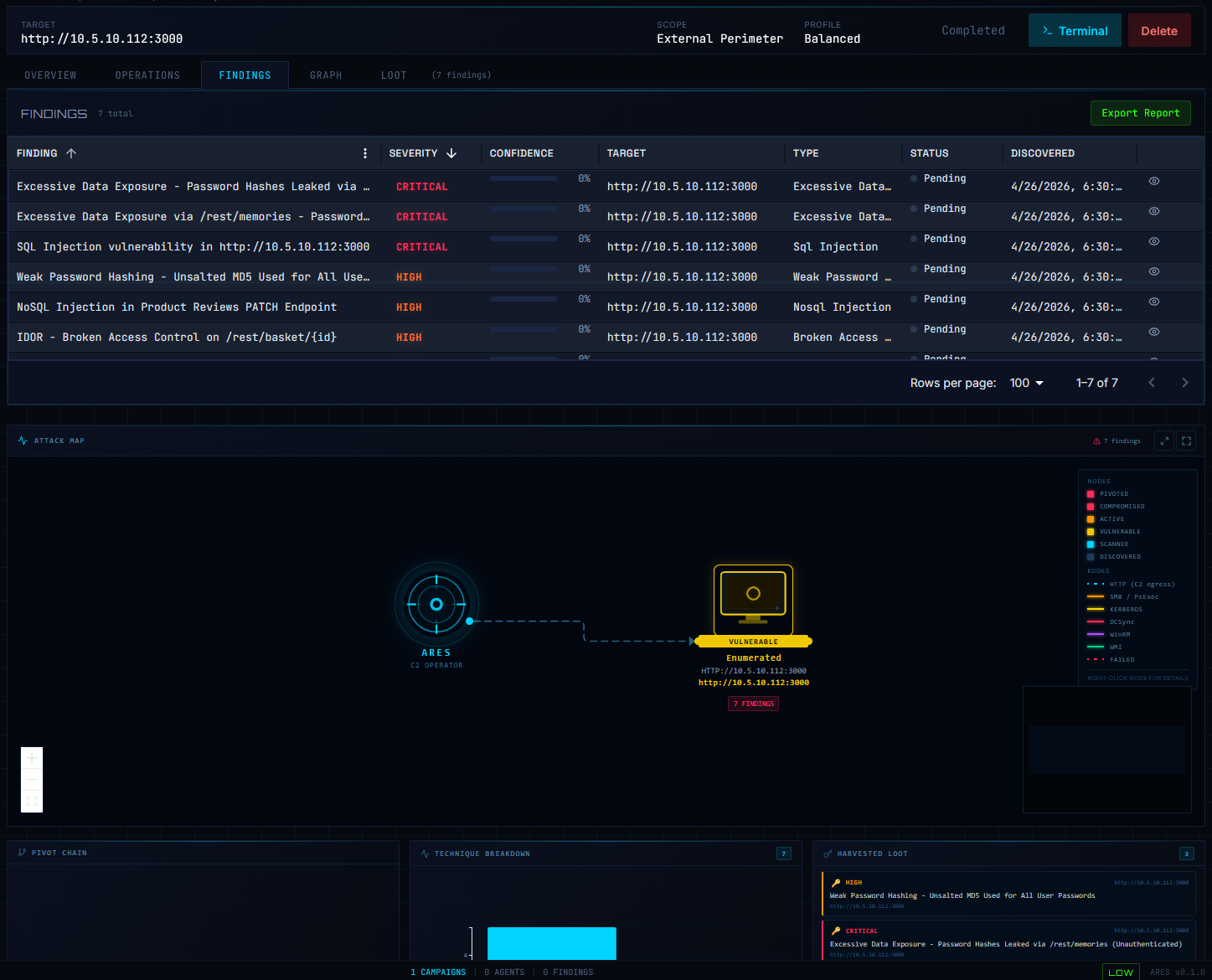
/rest/memories), classic SQL Injection, Weak Password Hashing (unsalted MD5), NoSQL Injection on a PATCH endpoint, and IDOR on /rest/basket/{id}. The attack map below renders live topology — nodes color-coded by state (Vulnerable, Compromised, Active, Scanned, Discovered), edges typed by access vector (HTTP, SMB, Kerberos, DCSync, WinRM).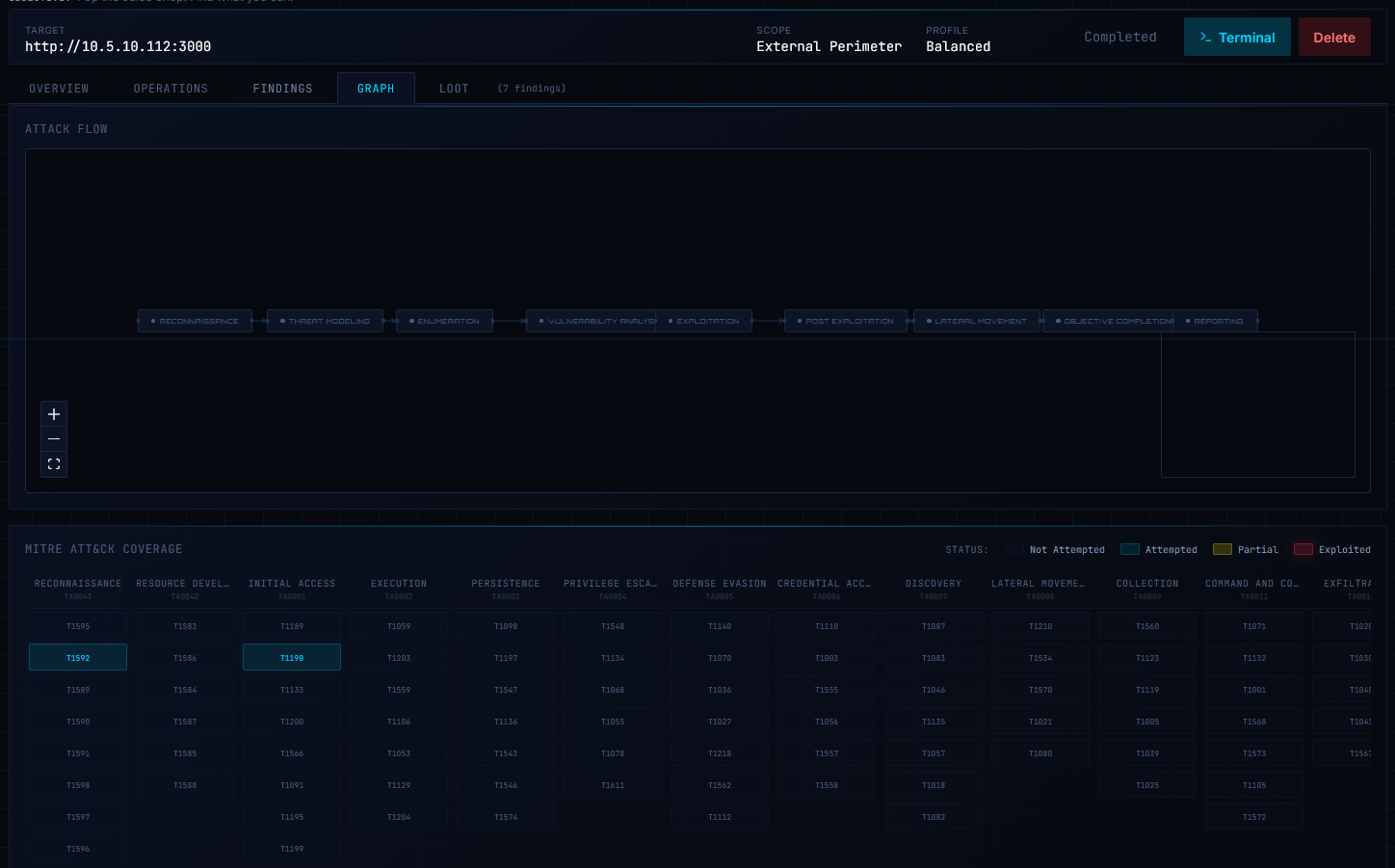
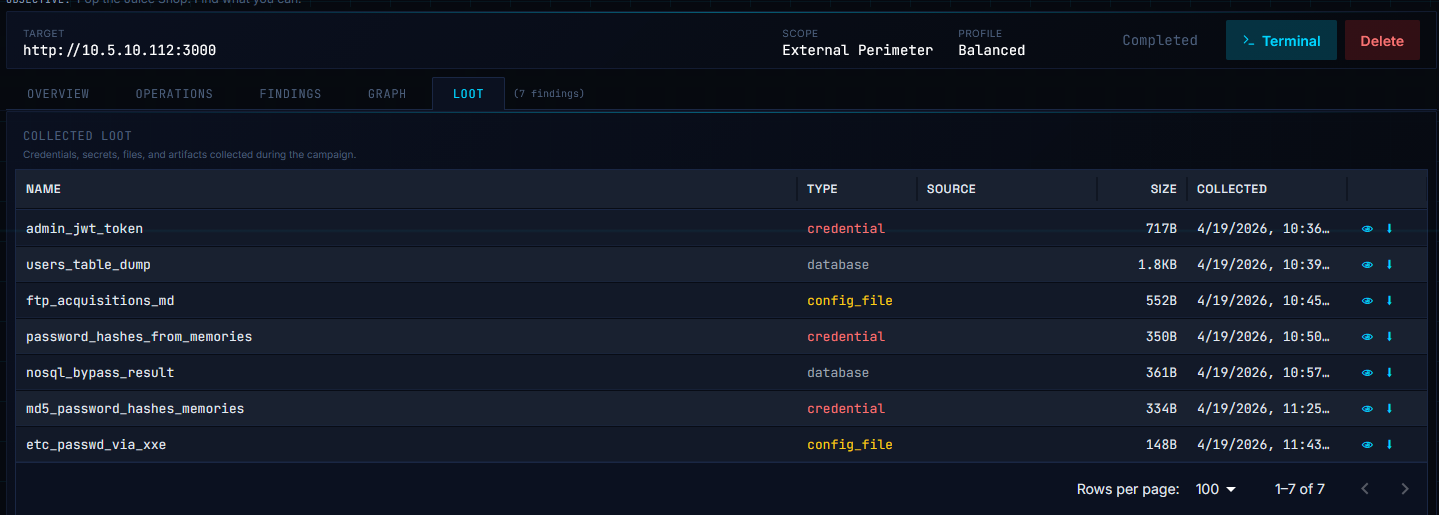
/rest/memories, an XXE-extracted /etc/passwd, and a NoSQL bypass result. The operator can review, export, or chain loot into follow-up campaigns without manual triage.The Juice Shop engagement above ran end-to-end in roughly an hour: from operator clicking "Start Autonomous Run" to seven validated findings, classified loot, and a completed campaign — with no human in the loop. Equivalent manual web-app testing would typically take 1–2 days. (All targets shown are from controlled lab environments — OWASP Juice Shop on the 10.5.x range and a GOAD Active Directory lab on 10.3.x.)
4. The Agent Framework: ReAct Loops and Scientific Method
Each agent in the system follows a modified ReAct (Reasoning + Acting) loop[5], extended with a scientific methodology we call REVIEW → HYPOTHESIZE → EXPERIMENT → PREDICT → CONTINGENCY:
MODIFIED ReAct LOOPEach agent cycles through five phases per reasoning step1. REVIEWObserve environment,
query knowledge graph2. HYPOTHESIZEForm attack hypothesis,
check failure registry3. EXPERIMENTExecute tool in sandbox,
collect evidence↓4. PREDICTCompare results to
expected behavior5. CONTINGENCYReflect on failure,
update approachFINDINGSubmit to validation
pipeline (L3)FAILED HYPOTHESES → FAILURE REGISTRY → PREVENTS RETRYING DEAD ENDS
Figure 6 — The modified ReAct loop. Each agent cycles through observation, hypothesis formation, experiment execution, and reflection. Failed hypotheses feed a failure registry that prevents retrying dead-end approaches.
4.1 Why Not LangChain/CrewAI/AutoGen?
We evaluated every major agent framework and built our own. Here's why:
- Tool execution model: Existing frameworks assume tools return immediately. Penetration testing tools can run for minutes (a full
nmapscan) or hours (a brute-force attack). We needed async execution with progress streaming, timeout management, and partial result handling. - Safety constraints: No existing framework has a concept of Rules of Engagement (ROE). Our agents must refuse to scan out-of-scope IPs, respect rate limits, and halt within 5 seconds of a kill command. This requires safety checks woven into every layer of the ReAct loop, not bolted on as middleware.
- Memory architecture: CrewAI's shared memory is a flat list. We need a knowledge graph (Neo4j) where an agent can query "show me all services running on hosts in the 10.0.0.0/24 subnet that have CVEs with CVSS > 7.0 and haven't been tested yet." Relational queries over graph-structured security data.
- Context management: With context windows of 128K–200K tokens, a naive agent burns through its budget in ~20 steps of verbose tool output. We implemented a context compression engine that preserves security-critical details (credentials, session tokens, vulnerability indicators) while summarizing verbose scan output.[6]
Multi-agent coordination trap: Google DeepMind found that 42% of multi-agent failures come from bad specifications, 37% from coordination breakdowns, and 21% from weak verification.[4] Adding agents without structured coordination makes systems dramatically worse, not better — the "17x error trap." Our layered architecture directly addresses all three failure modes.
4.2 The Procedural Fallback
A key architectural decision: every agent has a procedural (non-LLM) execution path. When the LLM is unavailable (air-gapped deployment, rate limiting, cost constraints), agents fall back to deterministic playbooks:
async def run(self, task: AgentTask) -> AgentResult:
if llm_available():
return await self._react_loop(task)
else:
return await self._procedural_execution(task)
The procedural path is less creative but guarantees forward progress. In practice, ~80% of an engagement's value comes from systematic enumeration that doesn't require LLM reasoning. The LLM shines in the remaining 20%: interpreting unusual error messages, chaining non-obvious vulnerabilities, and adapting to novel application architectures.
5. Campaign Orchestration: DAGs, Not Chains
A penetration test is not a linear sequence. Discovering an open SMB share might trigger Active Directory enumeration, which reveals a Kerberoastable service account, which leads to offline password cracking, which yields credentials for lateral movement. These are directed acyclic graphs (DAGs), not chains.
The orchestrator maintains a dynamic DAG of tasks:
class TaskDAG:
"""Dynamic DAG that grows as agents discover new attack paths."""
def add_task(self, task: Task, dependencies: list[str]):
# Cycle detection via DFS before insertion
if self._would_create_cycle(task.id, dependencies):
raise CycleDetectedError(task.id, dependencies)
self._graph[task.id] = TaskNode(task, dependencies)
def get_ready_tasks(self) -> list[Task]:
"""Return tasks whose dependencies are all completed."""
return [
node.task for node in self._graph.values()
if node.status == "pending"
and all(self._graph[dep].status == "completed"
for dep in node.dependencies)
]
5.1 Stall Detection
One of the hardest engineering problems: detecting when the system is stuck. We track three types of stalls:
- Agent-level: No progress events from a specific agent for N seconds. Solved with heartbeat tracking via the event bus — every tool execution and reasoning step emits a heartbeat.
- Phase-level: The entire phase makes no progress for M seconds. Force-cancels all running tasks and advances.
- System-level: Deadlock detection via resource dependency analysis. If Agent A waits for Agent B and vice versa, we break the cycle by canceling the lower-priority agent.
Lesson learned: Heartbeat tracking must be event-driven, not polling-based. Our initial implementation polled agent status every 30 seconds, which introduced a blind spot where an agent could stall, recover, and stall again without detection. Subscribing to agent.react_step and agent.tool_executed events via the bus eliminated this entirely.
6. Container Sandboxing: Trust Nothing
Penetration testing tools are, by definition, attack software. Running sqlmap or metasploit directly on your orchestration host is a recipe for disaster. In 2025, three runc CVEs (CVE-2025-31133, CVE-2025-52565, CVE-2025-52881) demonstrated mount race conditions allowing writes to protected host paths from inside standard containers.[7] Every tool invocation runs inside an isolated Docker container with gVisor as the container runtime.
SANDBOX ISOLATION MODELAgent ProcessPython asyncio • In-memory stateDocker APIContainer pool • exec_run() • Timeout enforcementgVisor SandboxUser-space kernel • Syscall interception • ~70% of 319 Linux syscallsNET_RAW onlyNo SYS_ADMIN, SYS_PTRACEEphemeral FSNo host mountsNetwork isolationTarget CIDR onlyTarget Networkiptables-enforced routing
Figure 7 — Sandbox isolation model. Agents communicate with containers via the Docker API. Containers have network access only to targets, and their filesystem is ephemeral.
6.1 Container Pool Management
Spinning up a container per tool invocation adds ~2–3 seconds of latency. For an agent executing 50+ tool calls per engagement, that's over two minutes of dead time. We maintain a warm pool of pre-started containers:
class ContainerPool:
"""Pre-warmed container pool with on-demand scaling."""
async def execute_command(
self, task_id: str, command: str, timeout: int = 300
) -> tuple[int, str, str]:
container = await self._acquire_container()
try:
exec_result = await asyncio.to_thread(
container.exec_run, command, demux=True
)
return (exec_result.exit_code,
exec_result.output[0] or b"",
exec_result.output[1] or b"")
finally:
await self._release_container(container)
Key design decisions:
- Tool PATH pre-checking: On startup, we probe every tool binary in the container image. Missing tools are added to an
_unavailable_toolsset, and agents are informed at task assignment time. - Runtime tool banning: If a tool exits with code 127 (command not found) during execution, it's banned for the remainder of the session.
- Image strategy: Two images —
pentest:lite(~2.7 GB, 30 tools) andpentest:full(~12 GB, 80+ tools). Both built from pre-compiled binaries, notgo installat build time, ensuring reproducible builds even behind corporate VPNs.
7. The Validation Problem: Zero False Positives
Here's a statistic that shaped our entire approach: SAST tools generate over 90% false positives — a study found only 180 of 2,116 flagged issues were real vulnerabilities.[8] DAST tools fare slightly better, but legacy scanners still show false-positive rates as high as 82% per the OWASP Benchmark.[9] When a scanner reports 200 "critical" findings and most are noise, operators learn to ignore the scanner.
Our design principle: accept false negatives, never false positives. If we miss a vulnerability, the operator might find it manually. But if we report a false positive, we erode trust in the entire system.
Design philosophy: We'd rather report 8 confirmed vulnerabilities than 20 "probable" ones. Every finding that reaches the operator has been validated through multiple independent checks that we're comfortable staking our reputation on.
7.1 The Cross-Agent Dedup Problem
This deserves its own section because it's a class of bug that's unique to multi-agent systems. Consider: Agent A discovers an XSS vulnerability at /search?q=<script>. Agent B, working independently, discovers the same XSS at /search?query=<script> (same endpoint, different parameter name). Agent C finds it through a form POST instead of a GET.
Same vulnerability, three different descriptions, three different evidence payloads. A naive deduplication system (hash the title + URL) would report all three. Our approach combines in-memory campaign-scoped dedup with database-level fuzzy matching:
# Simplified cross-agent dedup key
def _dedup_key(finding):
title_stem = finding.title[:40].lower().strip()
target = urlparse(finding.target).hostname or finding.target
vtype = finding.vulnerability_type.lower()
return (finding.campaign_id, title_stem, vtype, target)
8. Multi-Model LLM Strategy
Not all reasoning tasks are equal. Deciding which vulnerability to investigate next requires deep strategic thinking. Parsing the output of nmap -sV does not.
LLM ROUTING STRATEGYAgent RequestReasoning task classified by complexityLiteLLM RouterUniform API • 100+ providers • Automatic fallbackStrategicClaude, GPT-4 class
2–10s latencyTacticalLlama 70B, Mistral
0.5–2s latencyParsingLlama 8B, regex
<0.5s latency
Figure 8 — LLM routing. High-reasoning tasks route to frontier models, parsing tasks use local models. LiteLLM makes the routing transparent to agents.
8.1 Token Budget Management
Each campaign is allocated a token budget, subdivided by phase (reconnaissance, exploitation, validation). Agents track their consumption and receive warnings at 80% utilization. At 100%, they switch to procedural mode. The budget system enables adaptive allocation: reconnaissance surplus rolls over to exploitation, where creative reasoning adds the most value.
8.2 Air-Gap Capability
Offensive security work often happens in environments with no internet access. Our LiteLLM abstraction layer can route all inference to locally-hosted models (vLLM, Ollama) without any code changes. The same agent code runs against Claude's API or a local Llama instance — only the model quality changes, not the architecture.
9. Knowledge Graph: Why Neo4j
Penetration testing is fundamentally a graph problem. Hosts connect to networks. Services run on hosts. Vulnerabilities affect services. Credentials authenticate to services. Users belong to groups. Groups have permissions on resources.
"Find all paths from the compromised web server to the domain controller through services with known vulnerabilities" is a natural Cypher query:
MATCH path = (start:Host {compromised: true})
-[:RUNS]->(svc:Service)
-[:HAS_VULN]->(v:Vulnerability)
-[:AFFECTS]->(target_svc:Service)
<-[:RUNS]-(dc:Host {role: 'domain_controller'})
WHERE v.cvss >= 7.0
RETURN path
ORDER BY length(path)
LIMIT 5
Every discovery from every agent is written to the knowledge graph. When an agent starts a new task, it queries the graph for relevant context. This shared memory is what enables genuine multi-agent collaboration rather than N independent tools running in parallel.
10. Engineering Lessons (The Hard Way)
These are the bugs and design mistakes that no architecture diagram will show you.
10.1 Class-Level Caches Poison Tests
# DON'T: Class-level cache persists across test cases
class BaseAgent:
_execution_cache: dict = {} # Shared across ALL instances
# DO: Instance-level or explicitly clear between tests
class BaseAgent:
def __init__(self):
self._execution_cache: dict = {}
When agents cache tool outputs, that cache must be scoped to the campaign, not the class. We discovered this when test suite results became order-dependent — test #47 would pass in isolation but fail when run after test #12.
10.2 Docker ENTRYPOINT vs. exec
Our container image used ENTRYPOINT ["/bin/bash"]. When we ran docker run image evil-winrm -i target, Docker executed /bin/bash evil-winrm -i target — interpreting a Ruby script as a shell script. The error messages (require: command not found) were baffling until we understood the ENTRYPOINT mechanics. Solution: use docker exec (bypasses ENTRYPOINT) or set entrypoint="".
10.3 SQLite vs. PostgreSQL Compatibility
Tests use SQLite. Production uses PostgreSQL. The SQL function LEFT(column, N) exists in PostgreSQL but not SQLite. When we added cross-agent deduplication with func.left(title, 40), tests exploded. Solution: func.substr(column, 1, N) works in both.
10.4 Windows Named Pipes and Docker SDK
On Windows, the Docker SDK communicates via named pipes. The NpipeSocket class uses blocking I/O by default, which means a read() call will hang forever if the container produces no output. This leaked threads in our WebSocket shell proxy. Solution: settimeout(1.0) with a polling loop and _stop flag.
11. System Metrics
3,255+Tests Passing70+Sub-Agents45+Benchmark Tasks100+Vuln Templates30+Verified Tools
12. Technology Stack
| Component | Technology | Rationale |
|---|---|---|
| Runtime | Python 3.12+ asyncio | Async-native, rich security tooling ecosystem |
| API | FastAPI + Pydantic v2 | Auto-generated OpenAPI, request validation, async support |
| Graph DB | Neo4j 5.x | Natural fit for attack path modeling |
| Relational DB | PostgreSQL 16 | Findings storage, configuration, auth |
| Cache | Redis 7.x | Session state, rate limiting, pub/sub |
| Event Bus | NATS JetStream | Lightweight, persistent, at-least-once delivery |
| Object Storage | MinIO | S3-compatible, self-hosted, evidence artifacts |
| Frontend | React 18 + TypeScript | Real-time dashboard with WebSocket streaming |
| Containers | Docker + gVisor | Tool isolation with kernel-level sandboxing |
| LLM Routing | LiteLLM | Uniform API across 100+ model providers |
| Logging | structlog | Structured JSON logs, correlation IDs |
13. Conclusion
Building an autonomous offensive security platform is fundamentally a systems engineering challenge. The LLM is the reasoning engine, but the surrounding architecture — sandboxing, validation, orchestration, knowledge management — determines whether the system is useful or just impressive in a demo.
The key takeaways from our journey:
- Separate concerns ruthlessly. Agents reason. Containers execute. Validators verify. The orchestrator coordinates. No layer should do another layer's job.
- Design for failure. Agents will hallucinate. Tools will crash. Networks will timeout. Every component needs a degradation path that preserves system stability.
- Validate obsessively. A finding you can't prove is worse than a finding you missed. Build your validation pipeline before your exploitation pipeline.
- Budget everything. Tokens, time, container resources, network bandwidth. Unbounded consumption in any dimension will eventually bring the system down.
- Build the boring parts first. The knowledge graph, the event bus, the container pool — these aren't glamorous, but they're what make the system work at scale.
We're continuing to develop this platform in the open (within limits). Future posts will cover context compression strategies, knowledge graph schema design for security data, and the challenge of evaluating autonomous security systems without a ground truth.
References
- Munaiah, N. et al., "Characterizing the Skill Gap in Penetration Testing," IEEE Security & Privacy, 2024.
- Fortune Business Insights / Mordor Intelligence, "Penetration Testing Market Size," 2025. Market projected at $6.25B by 2032, ~12% CAGR.
- Bessemer Venture Partners, "Securing AI Agents: The Defining Cybersecurity Challenge of 2026," 2026.
- Google DeepMind, "Why Multi-Agent LLM Systems Fail," Dec 2025. Tested 180 configurations: unstructured multi-agent networks amplify errors up to 17.2x. See also: Galileo AI analysis.
- Yao, S. et al., "ReAct: Synergizing Reasoning and Acting in Language Models," ICLR 2023.
- Context compression for security applications requires preserving domain-specific tokens that generic summarization discards. See also: Liu et al., "Lost in the Middle: How Language Models Use Long Contexts," 2023.
- Three runc CVEs in 2025 (CVE-2025-31133, CVE-2025-52565, CVE-2025-52881) demonstrated mount race conditions allowing host path writes from standard containers. See Unit 42 analysis.
- Help Net Security, "91% Noise from Traditional SAST Tools," Jun 2025. Only 180 of 2,116 flagged issues were real vulnerabilities.
- AIMultiple, "DAST Benchmark: True & False Positive Rates 2025." Legacy DAST tools showed false-positive rates as high as 82% per OWASP Benchmark.
- Deng, G. et al., "PentestGPT: An LLM-empowered Automatic Penetration Testing Tool," 2023. Three self-interacting modules; 228.6% task-completion increase.
- Fang, R. et al., "HackSynth: LLM Agent and Evaluation Framework for Autonomous Penetration Testing," Dec 2024.
- NDSS 2026, "Context Relay for Long-Running Penetration-Testing Agents."
Section Index
| # | Section | Key Topics |
|---|---|---|
| 1 | Introduction | Operator leverage, market context |
| 2 | Architecture | 6-layer design, why not microservices |
| 3 | Platform in Action | Live campaign screenshots from lab environment |
| 4 | Agent Framework | ReAct loops, scientific method, procedural fallback |
| 5 | Orchestration | DAG scheduling, stall detection |
| 6 | Sandboxing | gVisor isolation, container pool, image strategy |
| 7 | Validation | Zero false positives, cross-agent dedup |
| 8 | LLM Strategy | Multi-model routing, token budgets, air-gap |
| 9 | Knowledge Graph | Neo4j, Cypher queries, shared agent memory |
| 10 | Lessons Learned | Real bugs: caches, ENTRYPOINT, SQLite, named pipes |
| 11 | Metrics | System scale numbers |
| 12 | Tech Stack | Full technology table |
| 13 | Conclusion | Key takeaways |
Published by the engineering team at sigoverrun.com